This applies to FreeBSD, but is similar on Linux.
Both the top and ps utilities will tell you what a given process is doing, which is generally running on a CPU or waiting for something. However, the documentation doesn’t really tell you what these states mean. The man page for the ps utility suggests reading the system source code. (sys/proc.h).
In this post I’ll deal with the common process states in top, the STATE column in the screenshot below.
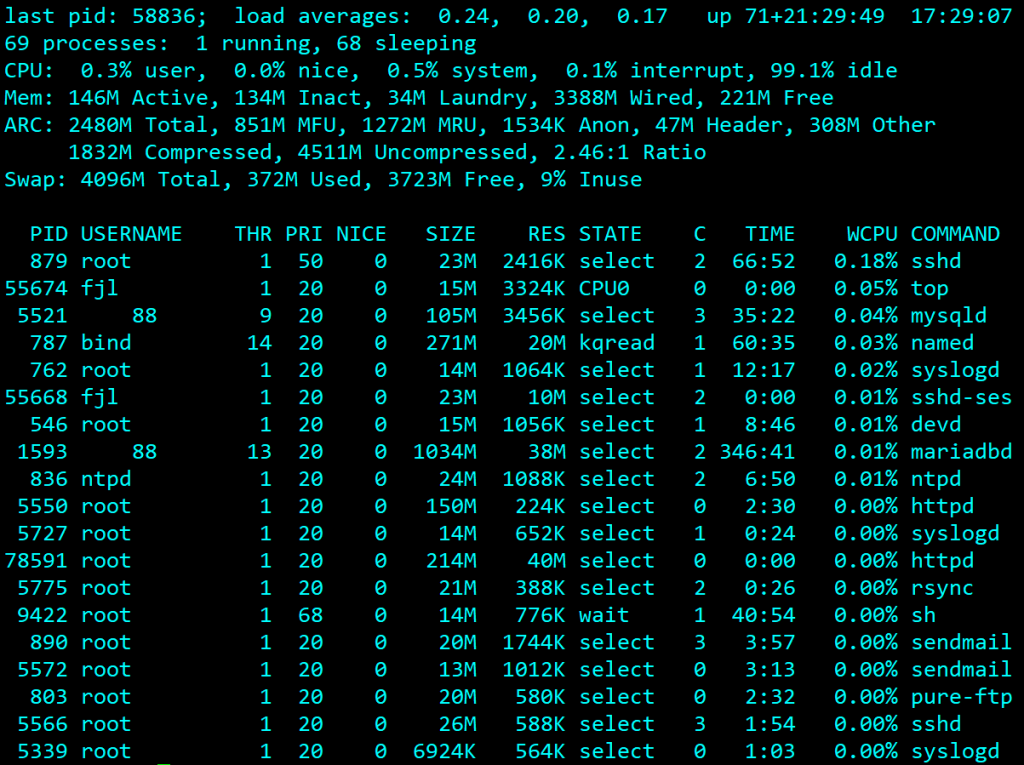
Other columns are:
- PID is the process-ID
- USERNAME the user that the process is running under.
- THR isn’t documented but I’m very sure it’s the thread count – i.e. the number of threads used by a multi-threaded process.
- PRI is the current process priority, and NICE is the nice value – an often misunderstood weighting used by the scheduler when determining the current priority. It’s outside the scope of this post.
- SIZE and RES are the total size of the process and the amount of real RAM currently being used, given it may have allocated memory that hasn’t been used yet or may be paged out.
- C is the CPU number to which the process is currently assigned
- TIME is the amount of CPU time (in seconds) the process has used since it was started.
- WCPU is the percentage CPU time currently being used by the process. Note that if you have four CPUs you can have 400% utilisation, as this applies to a single CPU.
And then, of course, there’s STATUS.
Officially, the status is one of one of “START”, “RUN”, “SLEEP”, “STOP”, “ZOMB”, “WAIT”, “LOCK” or the event being waited for. Run means it’s the currently running process, but SMP systems, RUN will be replaced by CPUn, where n is the CPU number doing the running. You’re unlikely to actually see the others as if a process isn’t running it’s going to be waiting for an event. But this is what they mean:
- START. A very short-lived state when the process is in the process of being created.
- SLEEP. The process can’t run as it’s waiting for an event (a character to be typed, a disk operation to complete and suchlike). In top you normally see the event being waited for, and these will be listed later.
- WAIT. A parent process is waiting for a child process to finish, or more accurately, change state. This means the parent process has called wait(), waitpid(), wait4() or similar (see man 2 wait for a full list).
- LOCK. The process is waiting until the kernel grants it a lock of some kind. You normally see the lock its waiting for prefixed with a ‘*’ rather than just plain “LOCK”.
- CPUn. The process is currently running on CPU n on an SMP system.
- RUN. The process is currently running on the single CPU.
- STOP. The process has been stopped (suspended) by sending it a SIGSTOP (e.g. by typing Ctrl-Z). It may be restarted using SIGSTART (or running fg/bg).
- ZOMB. A process has stopped but remains in memory as the parent hasn’t collected its exit status yet. This state doesn’t normally last long unless something’s wrong with the parent. You can’t kill a zombie process (the clue is in the name) so if you have one hanging around it will need a reboot to clear it – but don’t worry too much as it won’t be using much memory or other resources.
As I’ve said, you probably won’t see many of these as a process spends most of its time waiting for an event to happen, and in such cases, it shows the event in question. Common events are:
| STATE | Meaning | Reason or system call(s) involved |
|---|---|---|
| kqread | Waiting for an event to be posted to a kqueue descriptor | kevent() extremely common in modern servers (e.g., nginx, OpenZFS-related daemons, libevent-based apps) |
| sigwai | Waiting for a signal | sigwait(), sigwaitinfo(), sigtimedwait(); used by POSIX signal-handling threads |
| select | Waiting to read/write file. | Legacy select() or pselect() calls, still common but being replaced with kqueue/poll. |
| nanslp | Sleeping with nanosecond precision | nanosleep() or clock_nanosleep() used for timers, short sleeps, Rate limiting. |
| lockf | Blocked waiting on an advisory file record lock (byte-range lock) | Database or similar waiting to lock part of a shared file. fcntl(…, F_SETLKW, …) |
| accept | Waiting for incoming TCP connection | Classic blocking accept loop; seen in prefork servers, simple daemons calling accept() |
| pause | Suspended waiting for any signal | Used by older software (including the shell!) calling pause() |
| wait | Waiting for a child process to change state or end. | wait(), waitpid() etc. Very common for parent processes (shells, init-like processes, daemons that fork children) |
| CPUn | Actively running on CPU number ‘n’ | It may mean that the process is in a state that it can be given to a CPU, or it may actually be running. |
| sbwait | Waiting for socket buffer space (send) or data arrival (receive) | Socket I/O wait (e.g., TCP send buffer full or recv waiting) |
| biord biow | Blocked on block I/O read / write (disk/network filesystem operations) | Waiting for disk I/O completion |
| piperd pipewr | Blocked reading or writing to a pipe | Pipe I/O wait. Given pipes are now sockets you don’t see this on BSD any more (or at least, I don’t). |
| uwait | Userland wait | Often related to threading / synchronization primitives like pthread_cond_wait() , sem_wait() |